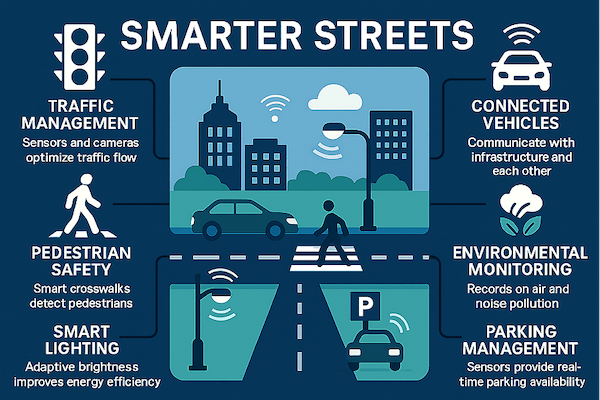
As the world races toward cleaner and smarter mobility, the Middle East is stepping on the accelerator. Electric vehicles (EVs) are no longer just a trend – they’re fast becoming a pillar of the region’s sustainable future.
Governments are acting with intent. The UAE has already converted nearly 20% of federal government vehicles to electric and aims for 30% of public sector fleets and 10% of all vehicles to be electric or hybrid by 2030. Saudi Arabia has set an ambitious target of 30% EV adoption in Riyadh by the same year. Similar ambitions are emerging across Oman, Bahrain, and Kuwait, supported by renewable energy targets and smart city plans.
But here’s the big question:
Is the EV charging ecosystem scaling fast enough to match this momentum?
Behind every successful EV rollout lies a strong location strategy, policy support, and usage trend analysis. For investors and stakeholders, these aren’t just operational details – they’re the foundation of a profitable and sustainable EV future in the region.
The GCC’s EV charging market is projected to grow from $2.04 billion in 2024 to $5.58 billion, reflecting a CAGR of 18.3% (Research and Markets). In the UAE alone, EVs could make up 25% of new vehicle sales by 2035 (PwC).
While consumer interest grows, the gap in high-speed, reliable, and accessible charging stations threatens to hold back adoption. This gap is where the most lucrative and strategic investment opportunities lie.
Planning Smart: The Importance of Location Strategy
To meet growing EV demand and support net-zero goals, location is everything. Strategic site selection doesn’t just boost convenience – it drives ROI by maximizing charger utilization and reducing infrastructure redundancy.
And while urban hubs often take center stage, rural and less-populated areas can’t be overlooked. Expanding access across all regions helps combat range anxiety and accelerates adoption. Smart location planning requires:
Maximize Utilization: Place chargers where demand is consistent to ensure high turnover and faster ROI.
Destination Charging: Install at high-dwell locations such as shopping malls, cafes, supermarkets, office, parking lots, parks, and highways where EV drivers naturally spend time
Think Beyond Cities: Rural and suburban coverage is key to building confidence among drivers.
Plan Around Constraints: In urban centres with limited space for grid upgrades, strategic deployment is even more critical.
Policy and Regulatory Drivers
Governments across the globe are stepping up to fast-track the electric vehicle revolution. From policy incentives to infrastructure mandates, public sector backing is stronger than ever.
Incentives & Subsidies: Grants, low-interest loans, and installation cost offsets to encourage adoption across municipalities and private developers.
Infrastructure Integration: Mandate EV charging inclusion in new construction, commercial buildings, smart parking facilities, and highway rest stops.
Banking Support: Financial institutions can step in with discounted interest rates, reduced processing fees, and flexible financing for chargers and accessories.
Public-Private Partnerships: Fast-track deployment through collaborative investments between governments, utilities, and private companies.
OEM Engagement: Attract automakers to the region to lower vehicle and charging costs, making EV ownership more accessible.
Public vs. Private Charging: Usage Patterns and Priorities
If mass EV adoption is the goal, public charging infrastructure is the gateway. It fills the gaps where private charging isn’t practical. It also plays a critical role in building trust and convenience for everyday drivers.
Here’s what’s driving public charging behaviour and where the returns lie:
Urban Demand is Surging: City centres see the highest need for public chargers due to limited private parking and home charging options. Stations in dense areas often achieve top-tier utilization, making them a smart investment with high ROI.
Highway Fast Charging: Chargers along intercity routes serve long-haul drivers and EV fleets gives users range confidence. Backed by government funding and paired with retail or rest stops, these hubs offer strong and predictable usage and make EVs viable for long-distance travel.
Home Charging is the Backbone: Most EV drivers charge overnight at home. It’s convenient, cost-effective, and ideal for daily top-ups. While direct profit is limited, bundling with smart grid or solar services creates added value.
Fleet Charging is a Commercial Power Play: Fleets such as delivery vans to taxis are shifting fast to EVs. Centralized depot charging with consistent, high-volume use delivers rapid ROI and makes fleet electrification a no-brainer for operators.
Infrastructure Challenges and Opportunities
While the EV revolution is racing ahead, the road isn’t without its bumps. From overloaded grids to inconsistent charging speeds, the technology powering EV infrastructure faces real-world limitations. But with the right solutions, these challenges become opportunities to lead.
Grid capacity and load management: Even the best EV chargers fail if the grid can’t handle the load. Many areas aren’t built for multiple fast chargers, causing delays, blackouts, and costly upgrades. At MWB, we conduct grid impact assessments and design smart charging frameworks to reduce strain, cut costs, and speed up deployment.
Limited Charging speeds: Fast chargers can fall short due to battery limits and weak power supply, causing slowdowns and reduced charger turnover. At MWB, we use GIS mapping and data modelling to pinpoint high-demand locations optimizing performance, user experience, and ROI.
Hardware reliability and maintenance: Frequent breakdowns from cheap hardware or poor maintenance don’t just frustrate drivers- they lead to underused assets and sunk costs. At MWB, we ensure reliability with tailored O&M plans, smart vendor selection, and remote diagnostics that keep chargers up and running.
MWB Powers the Shift
MWB provides comprehensive support to investors, developers, and utilities through a full-stack advisory and engineering offering. Their services encompass site selection and GIS-based planning, electrical infrastructure and load assessments, demand forecasting and financial modelling, as well as deployment planning and vendor advisory. MWB also guides clients through policy, permitting, and compliance processes, while offering strategic support for operations, maintenance, and uptime optimization.
Special Mention: This article has been co-authored by Prohit Keshavlal.
Meet The Author